Refactoring Distributed Big Balls of Mud
Der Begriff Big Ball of Mud 1 bezeichnet die Struktur einer Software, welche keine erkennbare Architektur besitzt. Es gilt als schlimmes, aber trotzdem häufig auftretendes Anti-Pattern. Schlimmer geht nicht.. oder doch? Distributed Big Balls of Muds 2 bezeichnet dasselbe Phänomen, bei welchem die Architektur jedoch verteilte Systeme beinhaltet. Solche Software ist schlecht wartbar und wird oft als legacy bezeichnet. Doch wie geht es damit weiter? Kürzlich hatte ich mit genau solcher legacy Software zu tun. Dieser Artikel beschreibt ein rein hypothetisches Vorgehen, wie man aus dem (wortwörtlichen) Schlamassel rauskommen könnte.
Der hier erwähnte Fall beschreibt ein System, welches als Cloud basierte Web-Applikation betrieben wurde. Es wurde versucht die Microservice-Architektur einzusetzen. Gründe für eine solche Entscheidung waren im Nachhinein schwer zu identifizieren. Vielleicht hat man nur den Aspekt berücksichtigt, dass die Entwicklungen in einer Microservice-Architektur an Performance gewinnen können.
Legacy Software
Die Definition von Legacy Software ist wohl für jeden eine andere. In diesem konkreten Fall waren folgende Punkte für mich Grund genug, diese Software als legacy und umbauwürdig zu bezeichnen:
Hoher Support-Aufwand: Das System war schwer verständlich. Fachliche Logik war durch die schnelle Entwicklungsphase über das ganze System verstreut. Zudem kamen diverse Workarounds- und Fehler hinzu. Fachliche Logik wurde mehrfach, aber trotzdem unterschiedlich und nicht zentral implementiert.
Hoher Operations-Aufwand: Das System wurde wie eine mechanische Maschine betrieben. Mal hat ein Entwickler da etwas manuell in der produktiven Datenbank korrigiert, mal mussten dort fehlerhafte Import-Daten manuell bereinigt werden. Produktivstellungen (Deployments) waren sehr heikel und mühsam, und somit auch nicht automatisiert. Die Datenbanken (und damit auch Teile im Code) waren im “extend only Mode”, weil man Angst hatte etwas kaputt zu machen.
Viele Defects / Bugs: Neue Anforderungen führten zu komischen Verhalten in anderen Teilen der Software. Wenn man einen Defect fixte, entstanden drei andere. All dies sind Indizien für legacy Software.
Wartbarkeit: 3 Die Wartbarkeit war nicht gegeben. Ich persönlich finde eine gute Messgrösse der Software-Wartbarkeit ist, zu schauen wie lange es dauert, bis neue Entwickler ein System erweitern, und im Fall von DevOps, auch selbständig betreiben können. Oft wird dieses Problem zwar erkannt, die Reaktion schlägt sich dann aber in einer ebenfalls nicht gewarteten Dokumentation nieder. Somit hat man noch mehr unwartbare Artefakte, welche neue Entwickler mehr verwirren als helfen.
Skalierbarkeit: In gewissen Teilen der Software wurde die nicht vorhandene Skalierbarkeit wohl erkannt. Statt diese Thematik jedoch aufzugreifen und zu diesem Zeitpunkt ein Refactoring anzustossen, wurde bewusst die Skalierbarkeit limitiert und eine technische Schuld aufgebaut.
Keine Tests: Leider waren überhaupt keine Tests implementiert. Automatisierte Tests waren von Beginn an kein Bestand der Lösung - dementsprechend niedrig war auch die Code-Qualität (Stichwort Kopplung etc.). Das wirklich erschreckende war jedoch, dass überhaupt kein Testing-Prozess vorhanden war. Bei Neuentwicklungen wurde meist nur der Nice-Case durchgespielt. Es gab keine Person (nebst den Entwicklern), welche das ganze System kannte und hätte testen können.
Code ohne Tests ist nicht sauber. Egal wie elegant er ist, egal wie lesbar und änderungsfreundlich er ist, ohne Tests ist er unsauber. (Robert C. Martin) 4
Fehlendes Entwickler Know-How: Dieser Punkt geht nicht zwingend unter legacy Software, dennoch beschleunigt er dessen Prozess. In diesem konkreten Fall wies sich dies in diversen Gebieten aus. Es gab zum Beispiel keine Entwicklungsumgebung. Ein lokal ausgeführter Service war immer mit der Datenbank sowie anderen Services aus dem Testsystem verknüpft. Dies machte nicht nur ein lokales entwickeln unmöglich, sondern sorgte auch dazu, dass die Testumgebung nicht isoliert war. Noch schlimmer war, dass die Services auf Datenbankebene miteinander integrierten.
Refactoring: Grobes Vorgehen
Als allererstes muss natürlich erkannt werden, dass das System legacy ist. Dies ist für Aussenstehende sicherlich einfacher als für Personen, welche von Beginn an dabei waren. Vielleicht wird erst versucht, bei den oben genannten Punkten nicht die Ursache sondern die Symptome zu bekämpfen. Man regelt und verstärkt bspw. den internen Support, oder man trennt Entwicklung und Operations auf (Dev vs. Ops statt DevOps). Alles aus meiner Sicht keine langfristigen Lösungen.
Als Entwickler muss man regelrecht dafür kämpfen, dass die subjektive Ansicht auf das bestehende System abgelegt wird und all die Probleme rein objektiv betrachtet werden. Man braucht viel Geduld und muss Lobbyarbeit für einen Umbau betreiben. Dabei ist ein gewisses Mass an Geduld, Kommunikationsfähigkeit und leider oft auch Politikwissenschaften hilfreich.
Im folgenden will ich ein Vorgehen beschreiben welches meiner Ansicht nach im konkreten Fall Sinn macht. Und ja, ich bin mir bewusst, dass allein einzelne dieser Punkte in einigen Unternehmen bereits Jahre dauern können.
1. Why?
Als allererstes würde ich die Frage stellen, wieso der Code jetzt Legacy ist. Was hat man falsch gemacht, dass man jetzt vor so vielen Problemen steht? Wieso wurde nicht rechtzeitig reagiert? Dies muss zwingend beantwortet werden, da ansonsten nicht die Ursache, sondern nur die Symptome (schlecht Software) angegangen werden. Kann man die Ursache nicht beseitigen, lohnt sich ein Refactoring schlicht weg nicht.
Im konkreten Fall hatte das “Wieso” verschiedene Gründe.
- Ein Grund war, dass man das Produkt schnell am Markt platzieren wollte. Dies an sich ist nicht schlecht. Wenn dabei jedoch Kompromisse sowohl in technischer, wie auch fachlicher Hinsicht eingegangen werden, und diese Schulden (Stichwort Technical Dept) nicht rechtzeitig abgearbeitet werden, so kann dies verherende Ausmasse annehmen.
- Ein weiterer Grund war, dass verschiedene Personen mit verschiedenen Ansichten ihre Anforderungen an die Entwickler herantrugen. Es gab keine zentrale Anlaufstelle, welche Konzepte genüberstellte, verglich und bei unsinnigen Anforderungen frühzeitig auf die Bremse trat. Alle diese Anforderungen kamen natürlich mit höchster Priorität.
- Die Entwickler gaben dem Druck nach. Leider arbeiteten die Entwickler nicht wirklich als Team zusammen. Das technische Niveau war nicht ausgeglichen, trotzdem wurde die Implementation von Features an einzelne Entwickler delegiert. Diese setzten diese meist einfachheitshalber in einem eigenenständigen Service, mit Integration auf Datenbankebene, um. Dieses Problem ist sicherlich organisationell bedingt und hätte z.B. mit einem agilen Ansatz verbessert werden können.
- Schlechte Architekturen. Die Architektonischen Entscheidungen waren schlichtweg falsch. Man wollte bereits von Beginn an Microservices implementieren, ohne deren Umfang zu kennen. Weder hatte man damit Erfahrungen gesammelt noch das technische Know-How um eine solch umfangreiche Architektur richtig umzusetzen. Auch die Anforderungen haben eine verteilte Architektur in diesem Masse nicht gerechtfertigt. Von diesem Standpunkt aus muss man den Entwicklern ein Kompliment machen, da sie trotzdem ein lauffähiges System entwickelt haben. Praktisch alle Architekten, welche die Microservice Architektur meisterten, erklären, dass ein Microservice-Ansatz bei einer initialen Produktentwicklung der falsche Weg sei. Sie empfehlen einen Monolithisch-Modularen Ansatz zu verfolgen, welcher sich später immer noch auftrennen lässt.
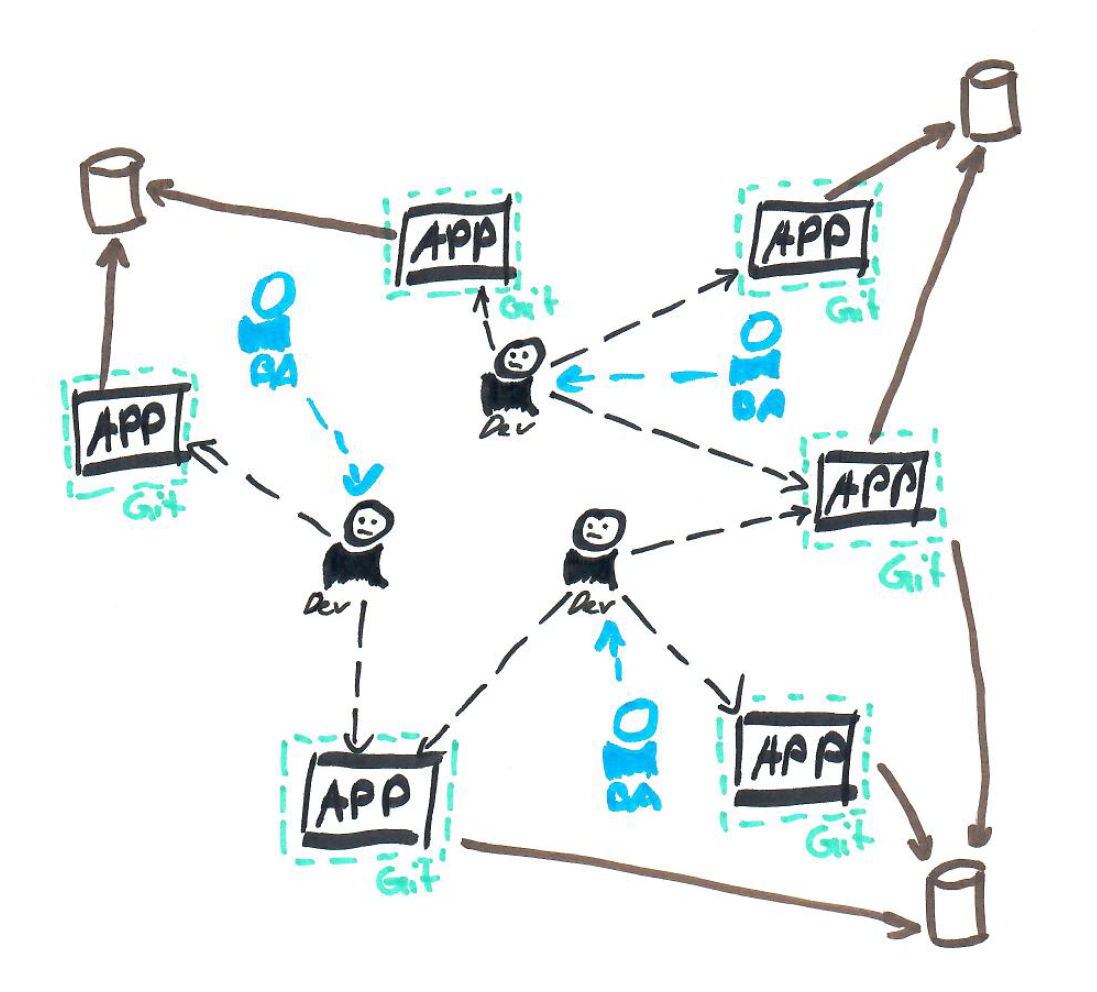
2. Conways Law
Ein Zitat, welches Personen auf Management-Stufe im Zusammenhang mit existierender legacy Software und schlechter Architektur wohl eher ungern lesen:
“Organizations which design systems […] are constrained to produce designs which are copies of the communication structures of these organizations.” –Melvin E. Conway
In diesem konkreten Fall hat es voll zugetroffen. Will man nun Umbauen, so sagt einem dieses Zitat jedoch auch was man besser machen kann. Ein erster Schritt ist also, ein Team aus agilen Softwareentwicklern in einem entsprechenden Umfeld arbeiten zu lassen. Optimalerweise gibt es einen Produktverantwortlichen, welcher die fachlichen Anforderungen im Griff hat und die Konzepte ausarbeitet sowie auf Sinnhaftigkeit prüft. Diese Person sollte auch in der Lage sein, bestehende Konzepte zu hinterfragen und nach sinnvolleren un einfacheren Lösungen zu suchen.
3. Fokus auf Fachlichkeit
Denkt man an einen Umbau, so treffen oft verschiedene Meinungen der Entwickler aufeinander. Der eine will Event-Sourcing einbauen, dem anderen reichen CQRS und sauberes Domain-Driven Design. Der Punkt ist, dass all dies nicht von belangen ist. Bei einem Umbau sollte man sich auf das fachliche, sowie die bestehenden Probleme konzentrieren. Man wird wohl nicht grundlegende Konzepte einfach so ändern können. Schrittweise ist dies sicherlich möglich, allerdings wird dies erst nach einigen Iterationen ersichtlich. Im Vorherein technische Visionen, Konzepte und Architekturen fix zu definieren macht bei einem solchen Umbau meiner Meinung nach keinen Sinn.
Trotzdem wird der Moment kommen, wo man bei der Architektur in eine gewisse Richtung lenken muss. Meiner Meinung nach muss das Entwicklerteam dazu weder hochqualifiziert sein, noch benötigt es eine zentrale Architektenrolle. Da das Team aus agilen Softwareentwicklern besteht, können diese alleine entscheiden wie sie vorgehen wollen. So soll auch das Entwicklerteam die technische Architektur zusammen festlegen und einen Level am Komplexität, Abstraktionen und Struktur finden, welchen alle Mitglieder Vertreten können.
Im angesprochenen Fall handelt es sich um ein System, welches produktiv war und bei welchem noch laufend neue Feature Anforderungen reinkamen. Ein Big Bang Umbau oder Neu- bzw. Parallel Umbau stand von Beginn an nicht zur Diskussion. Der Umbau sollte also in iterativer Manier vonstatten gehen, während das System betriebsfähig bleibt.
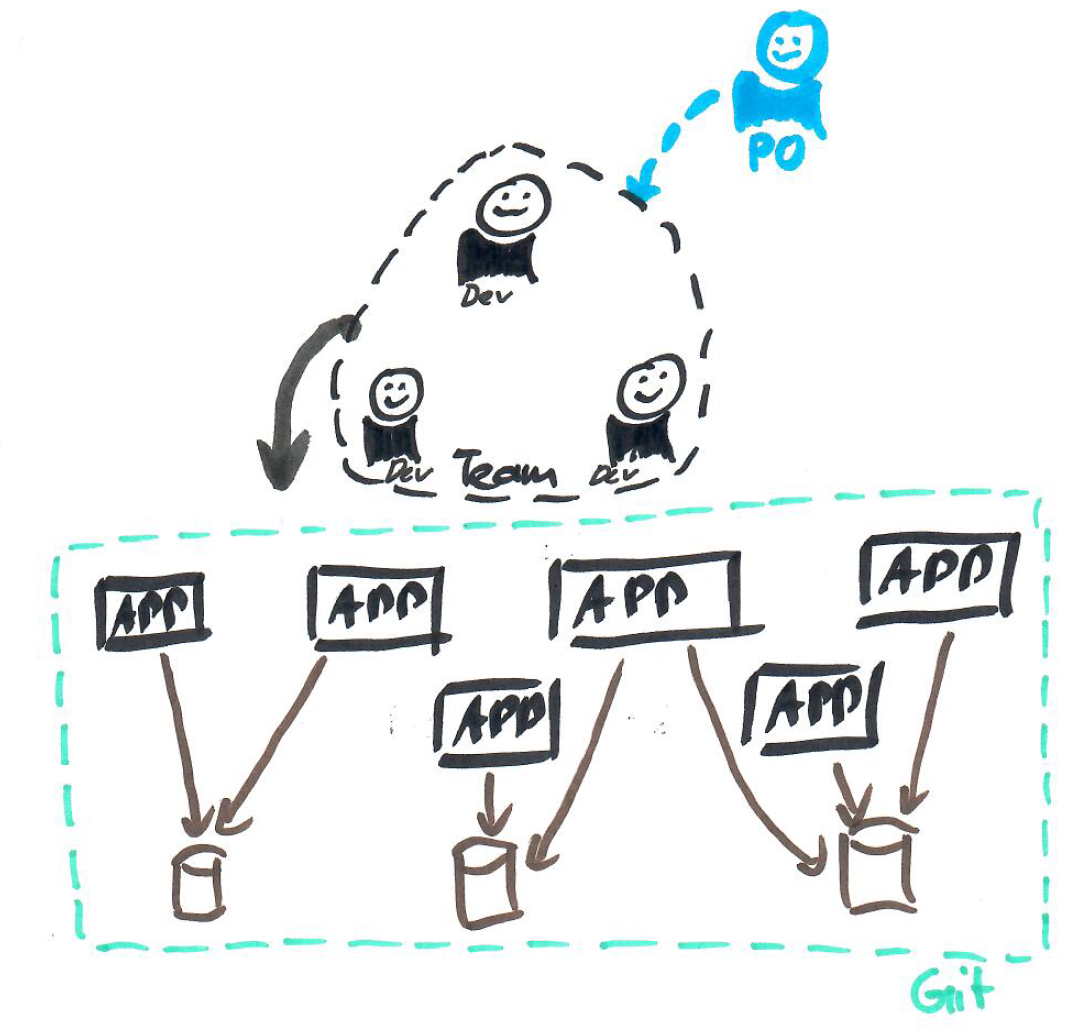
4. Kopplung akzeptieren
Das System war in mehrere Source-Code Repositories aufgeteilt. Zudem gab es noch einige (geteilte) Datenbanken. Da diese Datenbanken jedoch als Integrationspunkt zwischen den Services dienten, gab es kein Source-Code Repository welches der Owner einer Datenbank war. Dies führte natürlich dazu, dass eine lokale Entwicklungsumgebung sowie automatisierte Datenbankmigrationen unmöglich waren. Ja, das System war weit weg von Continuous Deployment. Auch automatisierte Tests gegen eine spezifische Datenbank waren so schlichtweg unmöglich.
Den einzigen Ausweg sehe ich darin, das ganze System vorerst in einem Source-Code Repository abzubilden. Somit akzeptiert man die Kopplung zwischen den zuvor vermeintlich unabhängig wirkenden Services. Dies bietet die Chance, das Deployment zentral zu regeln. Zudem hat man ein Source-Code Repository welches als Owner für die Datenbanken gilt. Dies führt dazu, dass eine lokale Entwicklungsumgebung sowie automatisierte Tests inkl. Datenbanken ermöglicht werden können. Dies natürlich nicht ohne grösseren Aufwand, aber zumindest besteht die Möglichkeit dazu. Dies ist wichtig für die nächsten Punkte.
Diese “Monolithisierung” der “Pseudo-Microservice Architektur” soll nur temporär von Bestand sein. Wenn gewisse Code-Teile zuvor Mehrfach Implementiert wurden, kann es Sinn machen diese so zu belassen. Ein schwerwiegender Fehler wäre nun, eine weiter Kopplung auf Code-Ebene hinzuzufügen.
Ein weiterer Vorteil im konkreten Fall ist, dass nun der noch nicht vorhandene DevOps (CI/CD) Prozess viel einfacher Implementiert werden kann. Es müssten dazu nicht mehr mehrere Repositories entsprechend aufgerüstet werden, sondern es kann nun alles zentral gelöst werden.
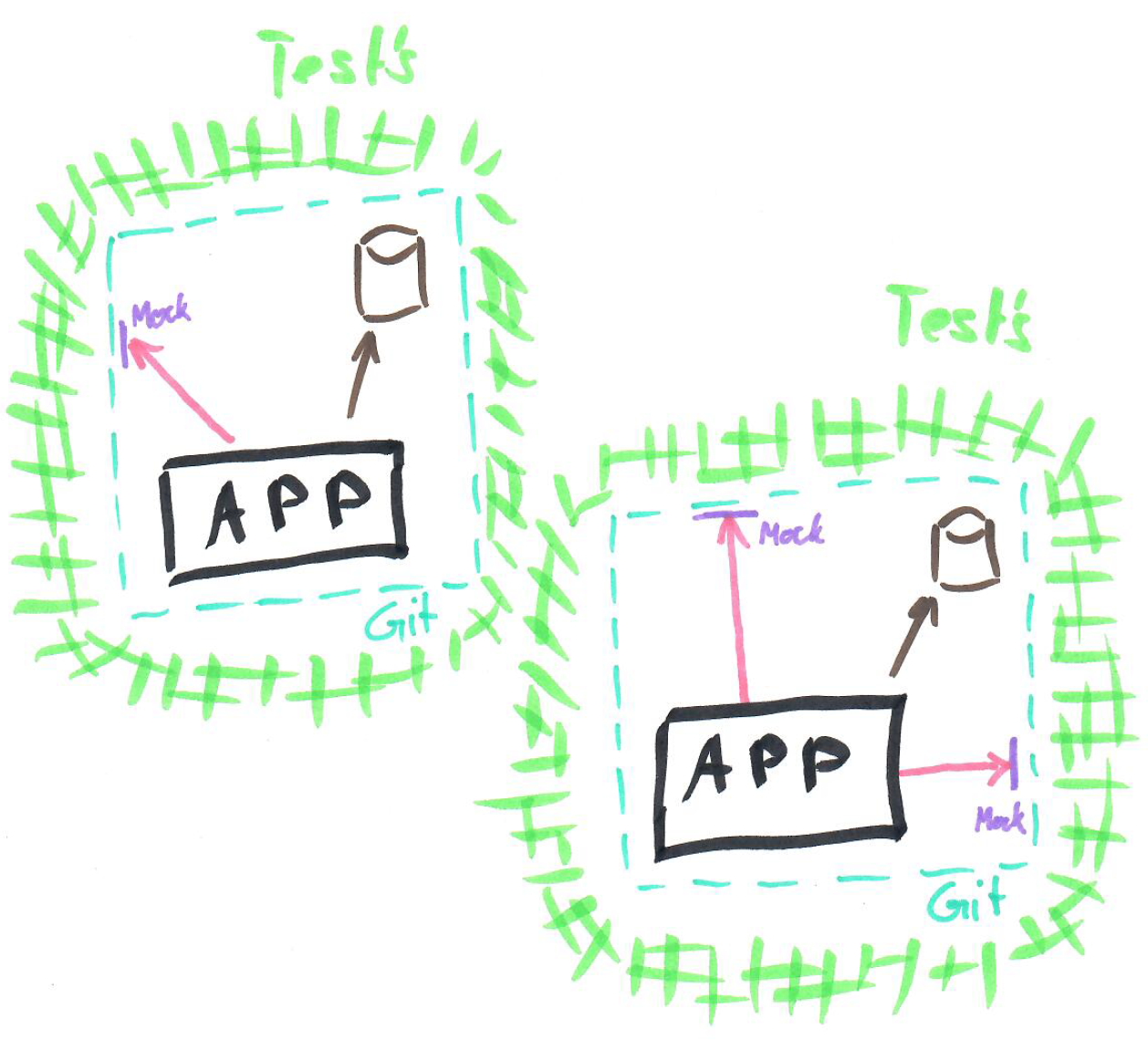
5. Entwicklungsumgebung komplett isolieren
Da man im vorgehenden Punkt nun den Schritt “zurück zum Teil-Monolith” gewagt hat, sollte nun eine komplett isolierte Entwicklungsumgebung möglich sein. Konkret bedeutet dies, dass alle Datenbanken lokal lauffähig, sowie automatisiert initialisierbar sind. Auch für Infrastruktur-Komponenten wie Message-Bus, Storage etc. sollten Emulations- oder Simulations- Lösungen vorhanden sein.
Nun müssen alle Schnittpunkte mit externen Systemen umgebaut werden. Im vorliegenden Fall waren eine ganze Menge an Fremdsystemen an das System angebunden. Leider war die Architektur nicht auf Austauschbarkeit ausgelegt (dies wäre wohl anders gewesen, wenn Tests von Beginn an implementiert worden wären). Das Ziel ist, dass für jedes Fremdsystem eine Fake-Implementation (oder Mocks etc.) gebaut und benutzt werden kann. Dazu ist es nötig, dass die Fremdsystemzugriffe entsprechend abstrahiert werden.
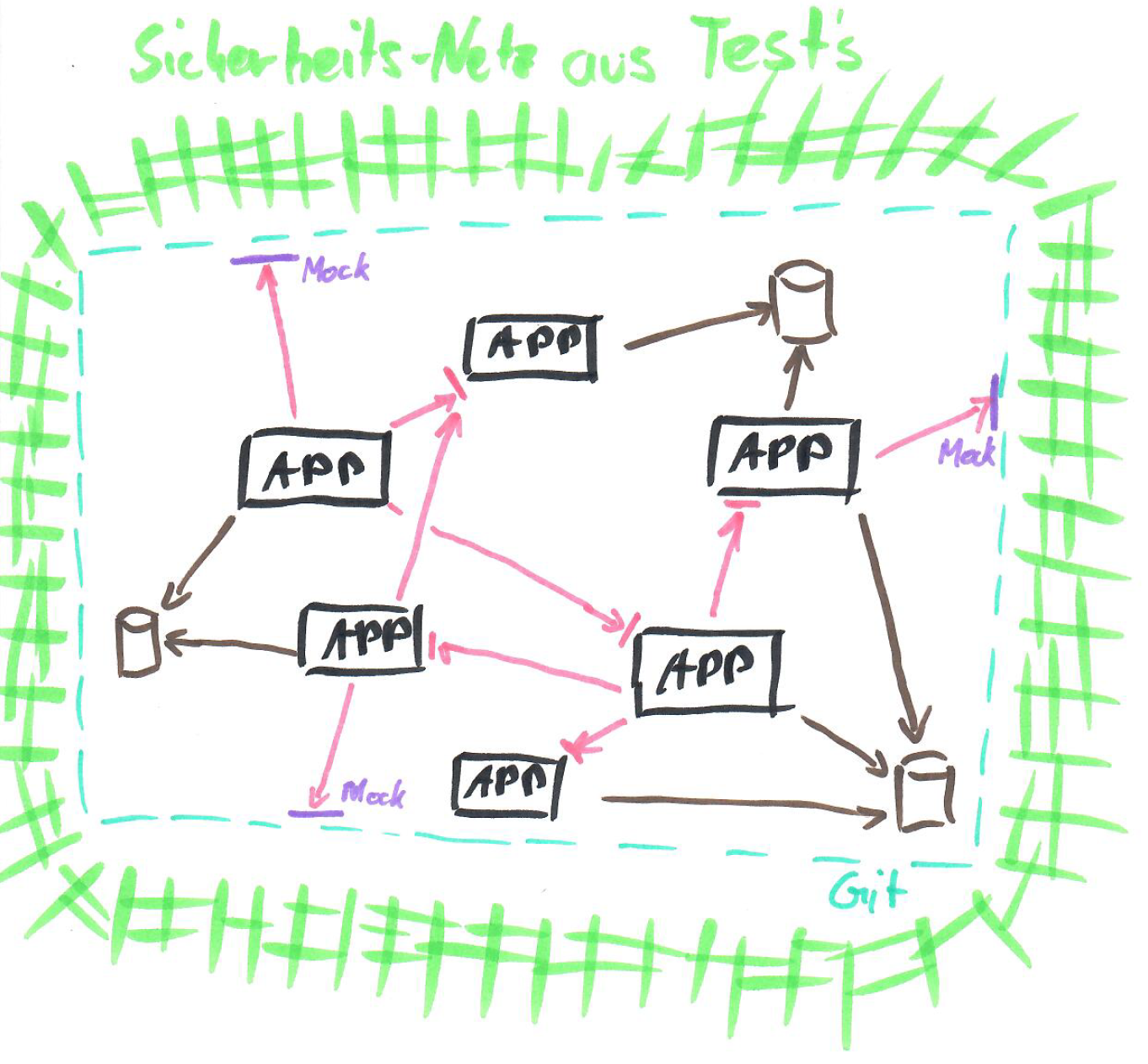
6. Sicherheitsnetz um bestehende Funktionalität
Da weder automatisierte Tests noch Test-Personen mit genügend Know-How vorhanden waren, sollte im ersten Schritt eine Art Sicherheitsnetz aus automatisierten Tests erstellt werden. Diese sollen während dem Umbau als Art Regressionstests dienen. Diese Tests sollen nicht an die Implementierung gekoppelt sein, da ansonsten beim Umbau auch die Tests angepasst werden müssen. Somit kann der Betrieb der Software auch während dem Umbau sichergestellt werden. Die Entwickler merken so, wenn sie etwas an einem Ecken der Software ändern und dies eine andere Ecke kaputt macht sofort. Im schlimmsten Fall kann dies auch eine manuelle Test-Person sein, welche sich der Aufgabe annehmen will. Diese muss dann quasi in der Lage sein auf Knopfdruck die Funktionalität des gesamten Systems sicherzustellen - und das in kurzer Zeit.
Natürlich wären Tests auf Unit- bzw. Integrationsebene sehr hilfreich. Diese für bestehende legacy Funktionalität, welche sowieso komplett Umgebaut wird, zu Implementieren wäre zu diesem Zeitpunkt jedoch reine Zeitverschwendung. Integrationstest um Komponenten, welche ihre Black-Box Struktur (Input / Output) behalten können durchaus Sinn machen. Bei den parallel neu zu entwickelnden Anforderungen, sollen diese aber zwingend implementiert werden. Im vorliegenden Fall war allerdings auch das Team zu Beginn schlichtweg nicht fähig dazu. Es musste Schulungsaufwand betrieben werden, um Themen wie automatisiertes Testing überhaupt den Entwicklern näher zu bringen.
7. Fachlich orientierter Umbau
Zusammen mit Fachspezialisten (Domänenexperten) sollte dann das bestehende System analysiert, und kritisch hinterfragt werden. Dabei sollen fehler- und lückenhafte Konzepte angesprochen und diskutiert werden und langfristige Lösungen ausgearbeitet werden. Es soll allen beteiligten klar werden wohin man will und wie man dorthin kommt. Spätestens hier sollte man die Fachexperten und das Business hinter sich haben. Mit einem iterativen Vorgehen soll dann Schritt für Schritt, neben Neuentwicklungen von Features, umgebaut werden. Zwischenstände sollen den Interessierten stets präsentiert und demonstriert werden, damit diese stets im Bilde sind und reagieren können.
Es gibt genügend Ansätze wie man Refactoring auf technischer Ebene durchführen kann. Man kann Neuentwicklungen komplett auslagern, temporäre Parallelentwicklungen machen, etc. Auch dabei sollte versucht werden kleinere “Big Bangs” zu vermeiden. Technisch ist diese Entwicklungsphase für das Team sicherlich eine grosse Herausforderung. Es wird teilweise etwas chaotisch im Code aussehen, Daten- sowie Code Replikationen werden entstehen. Wichtig ist, dass das Team konstant, konzentriert und fokussiert daran arbeiten kann. Es sollen stets alle informiert sein und nicht die ganze Verantwortung und Übersicht bei einzelnen, zentralen Personen liegen. Teamwork und Teamfähige Entwickler sind gefragt.
Während dem Umbau werden die zuvor entwickelten Tests als Regressionstests verwendet. Dies bietet allen beteiligten Zuversicht, dass trotz dem Umbau die Funktionalität gewährleistet ist. Es soll versucht werden so oft wie möglich zu releasen.
Die Fachschnitte der Services müssen nun je nach Anforderungen neu gemacht werden. Dazu ist es vielleicht Notwendig, zwei oder mehrere Services kurz- oder langfristig zusammenzulegen. Durch das Zusammenlegen kann der Grundsätzliche Aufbau geändert werden und der Fachschnitt neu angesetzt werden. Im konkreten Fall wird das Resultat sicherlich aus weniger Services bestehen als zu Beginn. Modularisierung kann auch ohne Microservice-Architektur erreicht werden.
Aus den gemachten Fehlern muss natürlich gelernt werden. Datenhoheiten müssen den fachspezifischen Services zugeteilt werden. synchrone Integration sollte vermieden werden, etc.